
Uploading Customer Data
This is a guide to uploading data to the Sparque Desk environment. Uploaded data in Sparque is grouped into "DataSets" which contain one or more files. These can be, among others, .csv, .xlsx, .sql, .json, or .xml files. Uploading files can be done manually by dragging and dropping them on the Sparque Desk or periodically using scripting tools.
Uploading Data Manually via Azure Storage Explorer
Data can be uploaded directly to Azure Blob Storage, where it is processed to create the next index. Using the Azure Storage Explorer is a manual process and is only intended for testing with irregular uploads.
You can download the Azure Storage Explorer directly from the Microsoft website here:
Azure Storage Explorer – cloud storage management | Microsoft Azure
After installing the storage manager, you need to connect to the container using your SAS URL. If you received more than one URL (a read and a write URL), you will need to use the write URL here to have write permissions. This is needed for uploading files. The SAS URL is a secure URL that contains credentials. Keep it safe as it provides read/write/delete access to your files in the blob storage.
If you need to upload new versions of the same data (product info, orders, etc.) on a daily basis, see Uploading Data Using Automated Scripts below.
Uploading Data via Automated Scripts
Data can also be uploaded using scripts that run on a server. The use case for this is a periodic script running on your server that creates exports of your data, then uploads them to Azure Blob Storage to create the next index. The upload must be configured on the client server and scheduled to run periodically.
Note: You must obtain a SAS URL that must be stored in a configuration file on your server. See the guidelines for your server's operating system below.
Uploading a File from a Linux Server
To set up the Azure uploader script, you can run this command via the command line on your server:
curl https://raw.githubusercontent.com/SPARQUE-AI/azure_uploader/main/install_linux_mac.sh | bash
After running this script, you should be in the ~/azure_uploader directory. There you will see the following script which can be run manually or scheduled:
./azure_upload_linux_mac.sh
Setting up the Configurations File (.env)
You need to specify your SAS token and the files you want to upload in an .env file, which should be in the same directory as your uploader script. By default, the script is installed in your home directory under /azure_uploader. A sample .env file:
SAS_URL="https://storage.blob.core.windows.net/mycontainer"
SAS_TOKEN="sp=adasdasd&st=2023-08-08T21:00:00Z&se=2035-08-09T09:00:00Z&spr=hsadasd..."
FILE_UPLOAD_PATH_1="/Users/MyUser/MyData/test1.txt"
FILE_AZURE_FOLDER_1="folder1"
FILE_UPLOAD_PATH_2="/Users/MyUser/MyData/test2.txt"
FILE_AZURE_FOLDER_2="folder2"Note:
FILE_AZURE_FOLDER_*variables must not contain special characters such as/ \ * ? #. Spaces are permitted in folder names. Up to 100 files are supported for upload.
Scheduling Periodic Uploads (Cron)
Running the script upload periodically should be done using Cron, which can be edited with crontab -e. Here is a sample crontab configuration that can be set up on your server. The server will run your scheduled uploads at 02:30 every morning.
30 2 * * * bash /home/ubuntu/azure_uploader/azure_upload_linux_mac.shUse contab.guru as a guide to schedule the upload at specific times of the day, if needed: https://crontab.guru/#30_2___*
Uploading from a Windows Server
To set up the Azure uploader script, you can run this command via Powershell (run as Administrator) on your server:
Invoke-Expression (Invoke-WebRequest -Uri "https://raw.githubusercontent.com/SPARQUE-AI/azure_uploader/main/install_windows.ps1").ContentAfter running this script, you should be in the azure_uploader directory. There you will see the following script, which can be run manually or scheduled:
.\azure_upload_windows.ps1
Setting up the Configurations File (.env.ps1)
You need to specify your SAS token and the files you want to upload in an .env.ps1 file, which should be in the same directory as your uploader script. By default the script is installed in your home directory, under /azure_uploader. A sample env file:
$SAS_URL = "https://storage.blob.core.windows.net/mycontainer"
$SAS_TOKEN = "sp=adasdasd&st=2023-08-08T21:00:00Z&se=2035-08-09T09:00:00Z&spr=hsadasd..."
$FILE_UPLOAD_PATH_1 = "C:\Users\MainUser\MyData\file1.csv"
$FILE_AZURE_FOLDER_1 = "folder1"
$FILE_UPLOAD_PATH_2 = "C:\Users\MainUser\MyData\file2.csv"
$FILE_AZURE_FOLDER_2 = "folder2"Note:
FILE_AZURE_FOLDER_*variables must not contain special characters such as/ \ * ? #. Spaces are permitted in folder names.Up to 100 files are supported for upload.
Scheduling Periodic Uploads (Task Scheduler)
To run the script upload periodically, we recommend using the Task Scheduler. To do so, perform the following steps:
Open the Task Scheduler in Windows (you can find it by clicking the Windows icon and using Search).
In the Task Scheduler, create a new basic task.
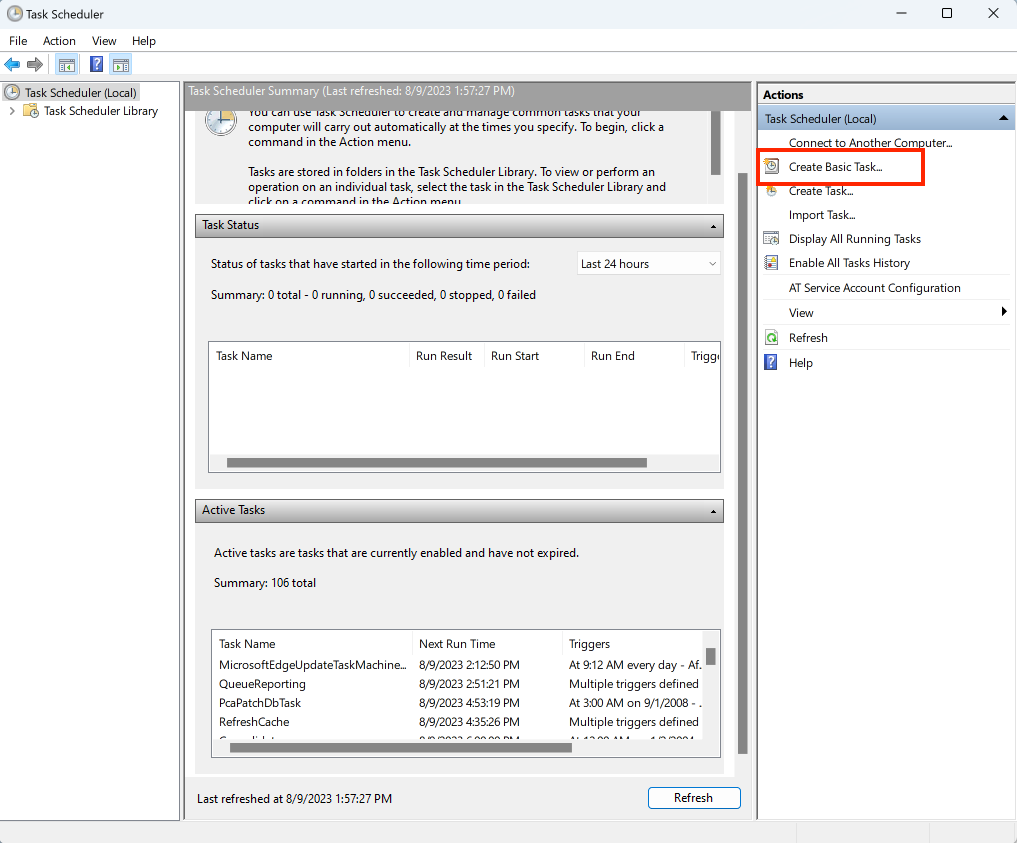
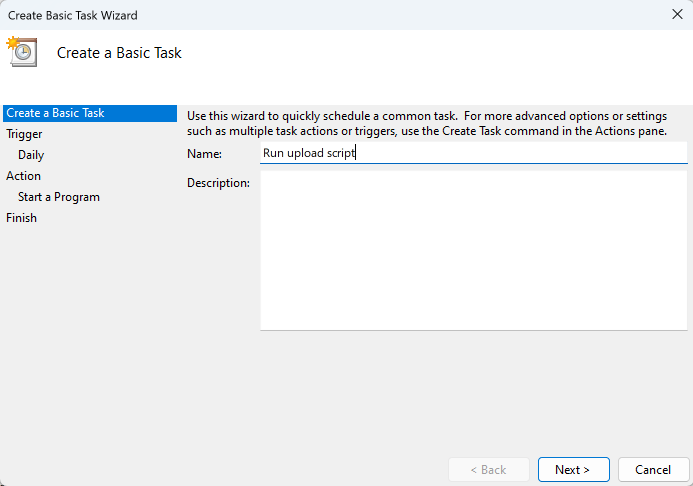
Give the task a memorable name.
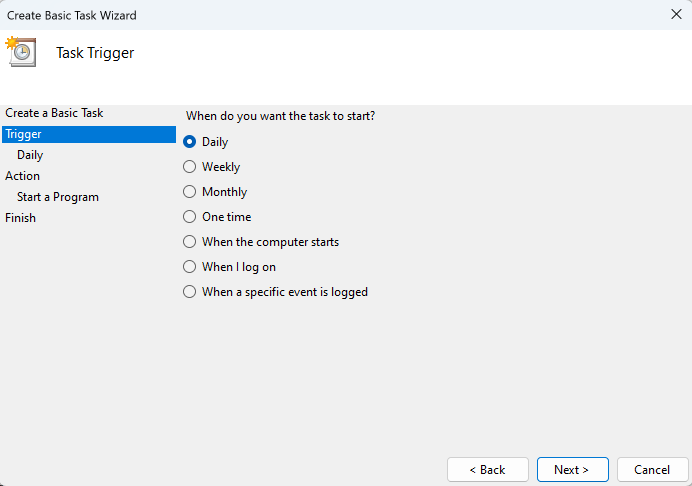
Set the Daily trigger frequency. This determines how often the task will run.
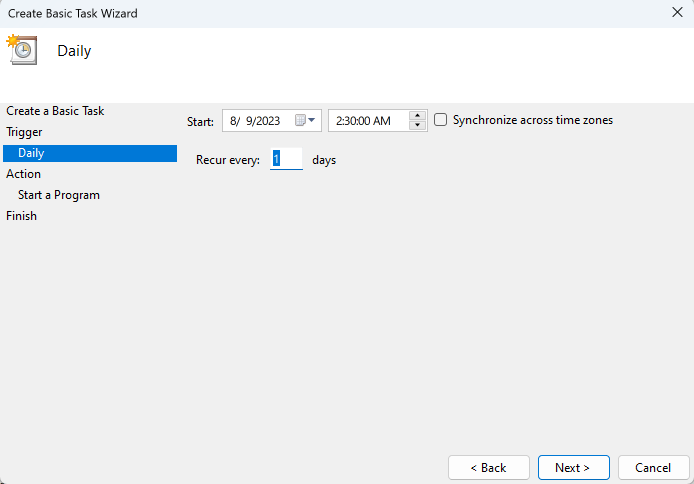
Specify a time to perform the uploads, ideally when your server load is as low as possible.
Select Start a program as the action to be performed.
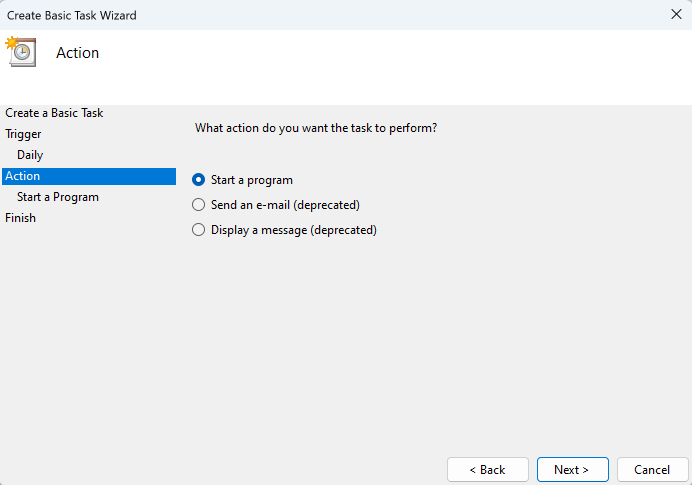
Click the Browse ... to select the upload script. After manually running the install script (see above), the upload script will be downloaded to users//azure_uploader. Here you should select the azure_upload_windows.ps1 file.
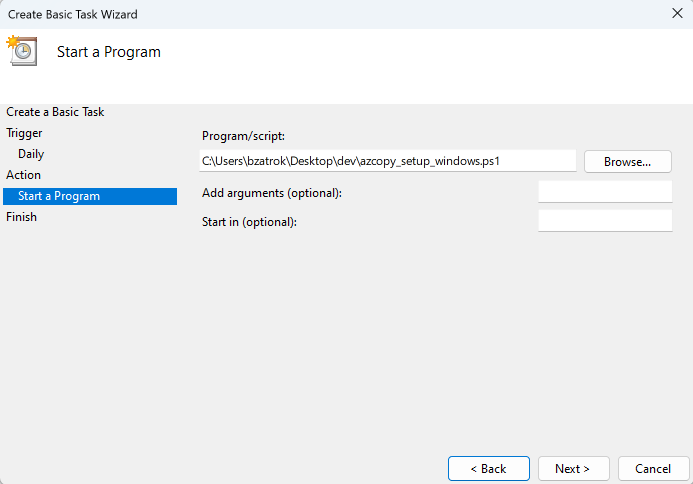
Review your settings and click Finish.
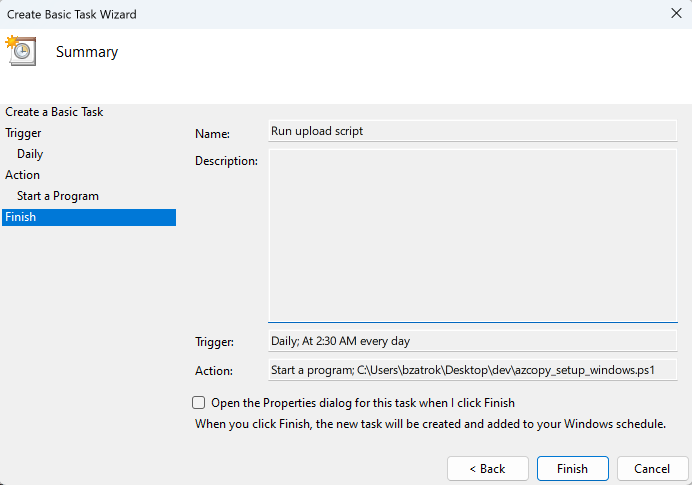
After saving and clicking Refresh, your task should be visible in the Active Tasks section.
Connected Pipeline Compression
To improve the speed of uploading your data, we recommend using connected pipeline compression, see Datasets | Connected Pipeline Compression for details.