Configurations
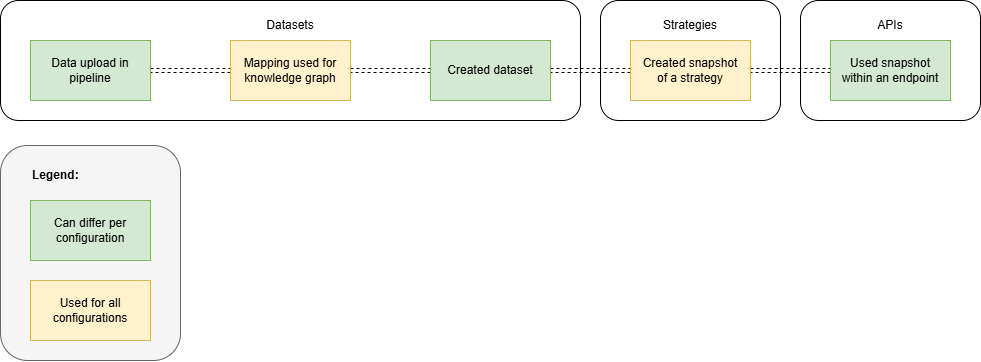
Sparque Desk leverages the concept of "configurations" to manage and deploy different states of datasets and APIs within its environment. A configuration is essentially a snapshot of the state of datasets, strategies, and APIs. This system allows for effective management and separation of different environments, such as testing, acceptance, and production, ensuring that each environment operates in its own isolated state.
Default and Production Configurations
By default, each workspace in Sparque Desk is initialized with a single configuration named default. In this configuration, users manage and prepare datasets, strategies, and APIs. When the setup in the default configuration is considered ready for production, Sparque generates a new configuration named production.
Default Configuration:
The default configuration is typically used for the initial setup and testing of datasets and APIs. It runs on a shared instance within the Sparque Desk environment.
Production Configuration:
The production configuration is a read-only snapshot created from the default configuration (or another specified configuration, such as preproduction). It runs on a dedicated machine, separate from the shared instance used by default, ensuring stable and isolated operations in a production environment.
Managing Multiple Configurations
To meet the needs of customers who want to test algorithms using data from different environments (such as test or acceptance), Sparque Desk supports the creation of multiple configurations beyond the default and production configurations. Currently, Sparque Desk allows deployment from either the default or preproduction configurations. Other environments are not supported.
Recommended Configurations
Default: Configure your datasets in Sparque Desk using data from your test environment. *
Acceptance: Configure your datasets in Sparque Desk using data from your acceptance environment.
Preproduction: Configure your datasets in Sparque Desk using data from your production environment. *
Production: This configuration is generated as an image from either the default or preproduction configuration and cannot be directly configured.
* Please note the following:
When using connected pipelines with Fetch from URL, the URL specifies the data source location. When creating a configuration image for deployment to production, the image references the data source specified in the configuration it was created from. Therefore, if you create an image from the default configuration for production, it will use the URL defined in the default configuration. Similarly, if you create an image from the preproduction configuration for production, it will utilize the URL specified in the preproduction configuration.
API Configuration Management
In Sparque Desk, the state of datasets and APIs may differ between configurations. To access a specific configuration via an API, you can modify the request by appending the ?config={{configuration}} parameter. This parameter directs the API to utilize the datasets and API states configured in the specified Sparque Desk configuration.
Important Considerations
API State Awareness:
APIs in different configurations may have different states. The API system recognizes if a newer snapshot of a strategy has been assigned to an API, which may affect other configurations.
Snapshot Hierarchy:
There is no inherent hierarchy between configurations in Sparque Desk. Updating an API in one configuration (e.g., default) will affect other configurations (e.g., acceptance, preproduction), but only if they are published afterwards.
Overwriting States:
If an API is updated in the acceptance configuration and subsequently in the default configuration, the state of the API in acceptance can be overwritten when the newer default configuration is published. Care should be taken to manage the timing and sequence of updates across configurations to avoid unintentional propagation of changes to production.