
Glossary
Annotation
A piece of documentation within a search strategy.
API
Acronym for Application Programming Interface: a software intermediary that allows two applications to talk to each other. In the context of Sparque Desk, it means the set of API endpoints that make up a service. For a typical search application there may be the following endpoints: an autocomplete, a search, a type-facet, an author-facet and a recommender endpoint. This set works as a whole; the service isn't complete if one of the endpoints in the set is not available. An active API is tied to a specific version of the data: each endpoint will yield information from the same version of the data (all endpoints will upgrade simultaneously).
See: Docs > APIs
API Endpoint
A component of an API that forms a touchpoint in the communication with other systems. In Sparque Desk, API endpoints are tied to search strategies to expose their functionality to the outside world.
An API endpoint is part of a Sparque request URL:
https://rest.sparque.ai/1/{WORKSPACE}/api/{API}/e/{ENDPOINT}/p/{PARAMETER}/{VALUE}/resultsIn the example below the 'search' endpoint of the 'movies' API is requested to return results for the query 'pulp fiction':
https://rest.sparque.ai/1/fliques/api/movies/e/search/p/query/pulp%20fiction/resultsAPI Output
The marker that defines which output connector in a strategy is selected as the output of the strategy as a whole:
API Template
A pattern an API Endpoint or a search strategy conforms to. It denotes the parameter(s) it expects and the type of output it returns.
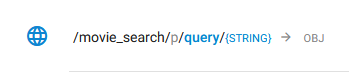
It can be found in the overview of endpoints within an API:
and in the toolbar of the strategy editor:

In this case, the endpoint/strategy expects the parameter 'query' of type STRING and returns results of type OBJ, an object from the database.
See: Docs > APIs, Docs > Strategies > Defining the API template
Attribute
Block
A constituent part of a search strategy. Each block performs an operation on the knowledge graph: filtering, ranking, transforming, combining, matching, etc. By combining blocks, operations of a higher complexity can be defined. Blocks are combined by connecting the output connector of one block to the input connector of another block.
Under the hood, a block contains a SpinQL snippet that defines how the probabilistic graph database should be queried in order to achieve the desired result.
Block Group
A set of blocks dedicated to a specific subtask within a search strategy.
Cache
Temporary space used to make strategies/APIs run faster.
Class
The specification of a concept.
Column Store (Database)
A type of database that stores data in a column-oriented model, making it highly scalable and fast to load and query. This makes it ideal for powering search engines.
Commit
An immutable instance of a Strategy Document.
Compiler
Depending on the context it can mean a block > spinql compiler, a spinql > sql compiler or a sql > mal compiler. Usually we mean the _spinql > sql compiler, which determines how to execute a search strategy and what to add to the cache to make execution most efficient.
Concept
A mental representation of a category of objects in a certain domain.
Connector
A small circle at the top of a block (input connector) or at the bottom of a block (output connector) that allows blocks of matching data types to be connected to each other.
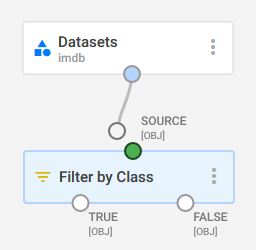
The output connector of a Datasets block being connected to the input connector of a Filter by Class block
Container
Describes how to access external data that needs to be loaded. May be flat files (like CSV, XML or JSON, XLSX), but also allows access to remote data (for example JDBC) or compressed contents.
Data Schema
The description of how data is organized in a database. In the case of a relational database it defines, for example the tables, their fields and the relations between them. See: Knowledge Graph
Dataset
A collection of data represented as a knowledge graph.
Data Pipeline
A combination of data sources and their mappings.
Data Silo
A data system that is incompatible or not integrated with other data systems. Data silos are created within organizations when different applications are used to conduct day-to-day business, each of which stores data in application-specific, proprietary formats. As a result, data is not adequately shared and remains trapped in a container like grain in a silo.
Data Source
Data in its raw form. Obtained either through files (like CSV, XML, JSON or XLSX) or through protocols (HTTP, JDBC).
Domain
A specific subject area for which an application is intended.
Edge
Endpoint
See: API Endpoint
Entity
Exploratory search
A search task people perform to find material dealing with a particular subject. See: Known-item search
Graph
Graph Database
A database that uses graph structures like nodes, edges, and properties to represent and store data. See: triplestore
Information Need
The type of concept a user needs to complete a (work) task or to satisfy the curiosity of the mind, independent of the method used to address the need, and regardless of whether the need is satisfied or not.
Information Retrieval
The computer science field that studies how information objects are obtained from a collection in response to an information need that is expressed by a user. Results are typically ranked on the relevance of the information object to the expressed information need.
Information Specialist
A person that is responsible for gathering, managing and disseminating data within organizations. Information Specialists have domain knowledge and are well-aware of the information that is available within an organization and its quality. In addition, they have a good understanding of the tasks that users perform with the use of data, of the challenges they encounter in their work and how search might help. Information specialists together with users can best determine which items a search application should return and in what order.
Input Connector
A small circle at the top of a block that indicates what type of data a block can have as input. An input connector can be connected to an output connector of another block if their data types match. Depending on the block, these can be one or more output connectors. If an input connector is connected to an output connector, this results in data entering the block and being transformed by the operation defined for the block.
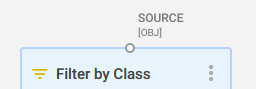
The input connector of a Filter by Class block
Knowledge Graph
A model that integrates data by storing concepts/entities/resources as linked data triples. As such, Knowledge Graphs do not have a fixed data schema and can be used to link any type of data, tiny or large, internal or external, structured, semi-structured or unstructured together into one rich model of a domain.
Known-item Search
A search task people perform to find a particular entity they know exists. See: Exploratory search
Linked Data (LD)
Data that is identified by Uniform Resource Identifiers (URIs). By identifying data this way, the meaning of data can be determined by looking up the URI and data from different sources can be integrated based on the URI. See: RDF, Triple, https://www.w3.org/DesignIssues/LinkedData.html
Linked Open Data (LOD)
Linked Data, which is released under an open license, which does not impede its reuse for free. See: https://www.w3.org/DesignIssues/LinkedData.html
Loading
The process of ad-hoc populating the knowledge graph (running the pipelines).
Mapping
The definition of how to map/interpret data in a pipeline to the knowledge graph constituents.
Node
Object
Output Connector
A small circle at the bottom of a block that indicates what type of data a block can have as output. An output connector can be connected to an input connector of another block if their data types match. An output connector can be connected to multiple input connectors. If an output connector is connected to an input connector, this results in data flowing to the connected block.
The output connector of a Datasets block
Parameter
A setting within a block or an input for an API endpoint.
Predicate
Probabilistic Graph Database (PGD)
A database that stores graph data and a probability estimate for every node and every edge. Essentially a triplestore is extended with a probability for every triple. This extension allows for the fusion of selecting and ranking: when selecting structured data from a database, one is presented with certain answers from facts; the probability estimates will be equal to one or zero. When ranking unstructured data, computers will never be certain about the degree of relevance of the result - here, the answer to a query is really a series of probable answers, produced by one ranking algorithm or another. The PGD stores facts with a probability of 1 and ranked results with a probability estimate that expresses their relevance. See: SpinQL
RDF
The Resource Description Framework: a data model that specifies how triples can be stored.
RDF store
See: Triplestore
Relation
Query Language
A computer language that is used to query a database.
Search Strategy
A combination of blocks in Sparque Desk. A search strategy results in a desired ranking of the entities in a knowledge graph. Under the hood, the constituent SpinQL snippets that make up the blocks define one complex SpinQL query that selects and ranks the desired entities in the probabilistic graph database.
Semi-Structured Data
Data that is described by markup. It doesn't conform to the strict structure of a relational database, but enforces hierarchies of records and fields within the data. Examples are XML and JSON. See: Structured Data, Unstructured Data
Snapshot
A version of a strategy that was explicitly named and saved to be used by an API endpoint or to be reverted to.
SpinQL
The query language Sparque developed to query the probabilistic graph database (PGD). For all operations on the PGD, it has been defined how to compute the resulting probabilities using SpinQL. SpinQL thus combines and propagates probabilities allowing the fusion of selecting and ranking.
SQL
Structured Query Language: the computer language that is used for managing data in a relational database.
Stacked Strategy
A Search Strategy that takes the output of another Search Strategy as its input.
See: Stacking Strategies
Strategy
See: Search Strategy
Strategy Document
The implementation of a search strategy.
Strategy Parameter
A parameter that is used within a strategy that can be filled in with a real value on demand.
Structured Data
Data that is stored in tables (typically in relational databases, spreadsheets, CSV’s etc.). It is often quantitative data, such as numbers and dates. Other examples are phone numbers, zip codes and customer names. See: Semi-Structured Data, Unstructured Data
Subject
Template
See: API Template
Test
An instantiation of one or more strategy parameters. If, for example a strategy parameter 'query' is defined, a test could be 'tarantino'. This simulates the case where the user of a movie site would search for 'tarantino'. For a test to be used for a strategy, it must match its API Template.
Testset
A list of tests.
Triple
A constituent part of a knowledge graph of the form subject, predicate, object. One resource (the subject) is connected to another resource (the object) via a relation (the predicate).
Triplestore
(Or RDF store): a purpose-built database for the storage and retrieval of triples.
Unstructured Data
Data that is stored in its native format. Even though it may have an internal structure, it's not structured in a predefined way. Unstructured data is often qualitative data, such as customer surveys and interviews. Other examples are text files, multimedia content and e-mail. See: Semi-Structured Data, Structured Data
URI
Acronym for Uniform Resource Identifier: a unique sequence of characters that identifies a resource used by web technologies.
Workspace
A closed environment within Sparque Desk in which designers can create datasets, pipelines, strategies, APIs, testsets.
XML Fragment
A (relatively small) piece of data (ideally no more than a few megabytes) coming from a container to be processed by the load process. A container specifies the size of the XML Fragment. Often, Containers provide mechanisms to influence the size of an XML Fragment.